1. Introduction
This simple lesson will give us a general idea of how to build a database system for an entertainment company. While the following content isn’t an exact representation of how Netflix has structured its data model, it serves as a guide for future developers to create their own systems.
2. Database Design
2.1 Content Table

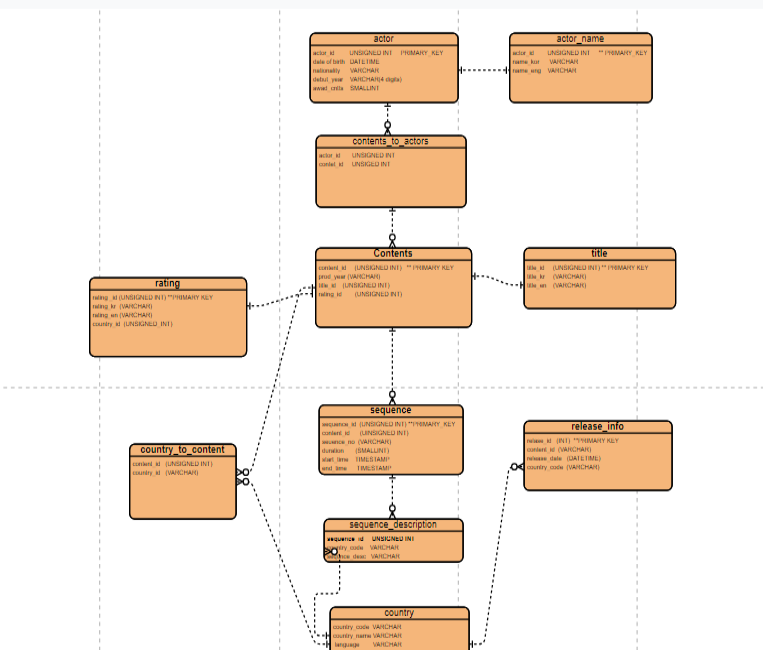
This table will hold all relevant information about content available to users, both now and in the future. First, we need a primary key to uniquely identify each record in the table. In this case, 'content-id' will serve as the primary key, and null records will not be allowed. We’ll also need extra columns to accommodate additional information about the content, including a country code, which will consist of two digits in string format. Additionally, 'rating_id' will be included in our table, serving as a reference to the primary key in the 'rating' table.
| Name | Type | Feature |
| content_id | UNSIGNED INT | - 11 digits in a string format - primary_key |
| country_id | VARCHAR | - a country producing the content - 2 digt in a string format |
| release_year | VARCHAR | - 4 digit in a string format |
| title_id | UNSIGNED INT | - a primary key in 'table |
| genre_id | UNSIGNED INT | - The fild indicates the types of contents ex) commedy, horror, .. - |
2.2 Title
Most major tech companies, like Netflix, have a diverse user base from many different countries. Therefore, it makes sense to create a separate table to hold title information in various languages, or at least in the most commonly used ones.
| Name | Type | Features |
| title_id | UNSIGNED_INT (PRIMARY KEY) | - 11 digits in a string format |
| title_kr | VARCHAR(40) | - title in Korean |
| tile_en | VARCHAR(40) | - title in English |
There is only one corresponding content record for each title ID. Therefore, a one-to-one relationship will be established between the 'contents' table and the 'title' table.
2.3 Rating
Every piece of content worldwide should have a rating that indicates its suitability. The main challenge is the lack of a universal or standardized system for these ratings. As a result, developers need to collect ratings from different countries and map each one to the correct label.
| Name | Type | Feature |
| rating_id | UNSIGNED_INT (PRIMARY KEY) | - 'ratings.rating_id' is referecning |
| rating_en | VARCHAR(10) | - A general category of ratings + G + PG-13 + R + NC-17 - A column acting as a reference |
| rating_kr | VARCHAR(40) | - ratings in Korean + 모든연령관람가 + 12세 이상 관람가 + 15세 이상 관람가 + 청소년불가 |
2.4 Country
In a special case, where a movie can be made in multiple countries, you'll need to create a many-to-many relationship between the movies and countries tables. This is a common scenario in database design when an entity (like a movie) is associated with multiple instances of another entity (like countries), and vice versa.
To establish this relationship, you need an intermediate or junction table. This table will map the relationships between movies and countries by storing references to both.
The Country table is connected to several other tables in our ER diagram. Any table that includes the 'country_code' field will have a relationship with the Country table, which ensures consistency and allows us to maintain standardized country information across different entities.
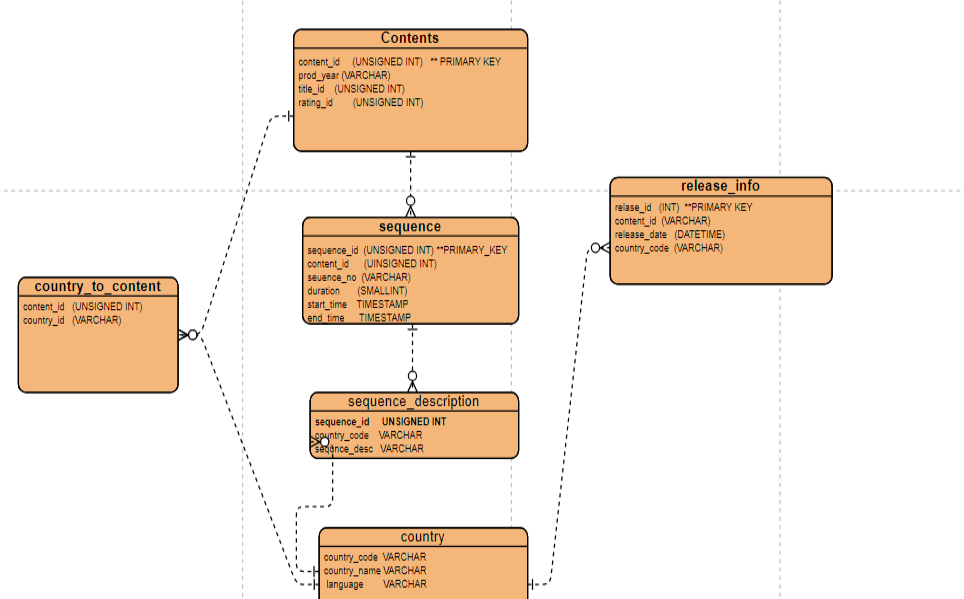
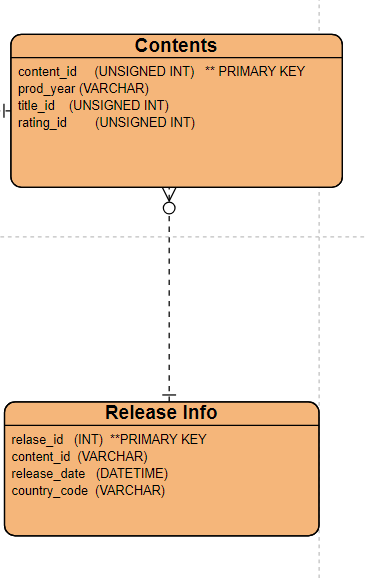
2.5 Release Info
You can create a table named release_info that includes fields for the release date, country, and a reference to the content. This table will store multiple entries for each movie if it was released in different countries on different dates.
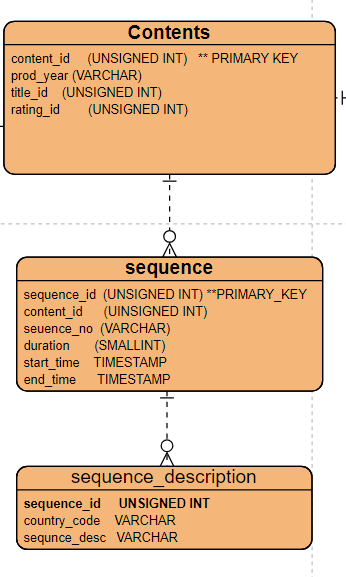
2.6 Sequence Table
To store sequences of a movie, you can create a sequences table that contains information about different scenes or sequences within a movie. This table could include fields like sequence ID, movie ID, sequence number, description, duration, and any additional metadata relevant to each sequence. However, we could consider moving one field to a separate table. The 'sequence description' should be available in different languages, so it would be beneficial to create another table called 'sequence_descrp' to store the descriptions in various languages.
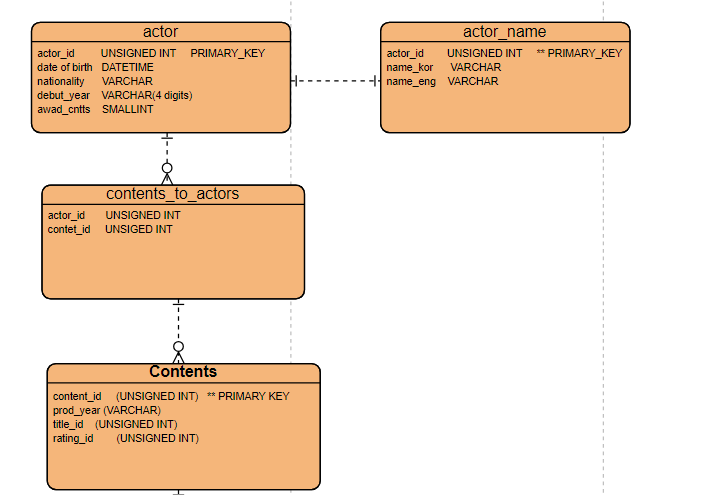
2.7 Actor
The first approach is to store all the relevant information about actors in a single table. This structure works well for domestic companies whose primary audience is within a specific country. In such cases, the database is simple and efficient, as there's no need to accommodate multiple languages or complex relationships.
However, for international companies, where different languages need to be supported—including variations in actor names—the single-table approach becomes limiting. For example, the full names of actors may need to be available in various languages to cater to different markets. In this scenario, a more flexible approach would involve separating multilingual data (like actor names) into its own table, allowing for easier management and expansion as more languages are added.
To establish a relationship between multiple instances of two different entities, an intermediate or junction table is needed. In our case, the contents_to_actors table acts as the junction table that links the content table to the actor table. This intermediate table helps manage the many-to-many relationship, where a single piece of content (such as a movie) can feature multiple actors, and an actor can participate in multiple pieces of content.
3. Conclusion
Even though real-world database structures are often much more complex than our example, this provides us with a valuable opportunity to understand how general database systems operate. By working through these simplified cases, we can gain insights into the fundamental principles of database design, such as managing relationships between entities, ensuring data consistency, and optimizing for efficiency. These concepts form the backbone of more complex systems and help us appreciate the underlying mechanics of how databases handle intricate relationships and large volumes of data.